n8n 雙 LLM 工作流:OpenAI 跟 Claude 什麼時候用哪個?2026 路由實戰
n8n 雙 LLM 工作流靠 OpenAI 跟 Claude 分工:結構化輸出走 GPT、長文敘事走 Claude,本文拆解選型表、3 種路由架構(靜態 Switch、AI Classifier、Primary+Fallback)與 10 萬請求成本實算,立即套到你的 workflow。
n8n 雙 LLM 工作流:OpenAI 跟 Claude 什麼時候用哪個?2026 路由實戰
n8n 雙 LLM 工作流是把 OpenAI 跟 Claude 兩家模型在同一條 workflow 裡分工,透過任務分類器與 Switch 節點動態路由,解決單一模型在成本、品質與速度上難以兼顧的問題。
你是不是也遇過這個狀況:客服機器人用 GPT-4o 答得很順,但寫 1500 字的長文總是太罐頭;改用 Claude 後文章好讀很多,可是接 function call 跟結構化輸出又出現 bug。再加上每月 API 帳單不停往上爬,老闆問你「為什麼上個月燒了 8 萬塊」的時候,你拿不出帳。
雙 LLM 不是要你押兩家、繳兩份月費。重點是:讓對的任務找對的模型。OpenAI 跟 Claude 在 2026 年這個時間點,強項已經拉開差距,不是「誰比較強」的問題,而是「在我這條 workflow 裡,這一步該丟給誰」。本文用 n8n 把這件事做成可重複的路由架構,並附選型表、3 種實作方式與成本實算。
如果你還沒做過 n8n AI Agent,先看 n8n + Claude AI 客服自動化建置教學 把基礎打穩;如果你想看「Claude Skills 怎麼接進 workflow node」這類更架構面的延伸,可以一起參考 n8n MCP integration:把 Claude Skills 變 workflow node。成本路由的數字版可以對照 多 LLM 路由的成本分流策略,本文聚焦在 n8n 工作流怎麼搭。
為什麼單一 LLM 撐不住整條 workflow
很多人一開始 workflow 只接 OpenAI 一家。前幾週很順,越往後越卡。常見痛點有四個。
第一是任務型態不一。一條完整的客服流程裡,意圖判斷只需要分類,會議摘要要長文寫作,FAQ 比對要向量檢索後再生成,工單分派要結構化 JSON,最後再寫一段給人類看的回覆。這五件事用同一個模型、同一組 prompt 處理,誰都不夠專。
第二是價格梯度沒拉開。API 帳單會爆衝,多半不是「呼叫次數」的問題,而是「該用便宜模型的地方用了貴模型」。意圖分類用 GPT-4o 或 Claude Sonnet 都是浪費;長文寫作用 mini 系列又會品質崩。
第三是模型故障時整條 workflow 一起斷。OpenAI 在 2024 年 6 月、12 月、2025 年 5 月都出現過 90 分鐘以上的服務中斷。如果你把所有節點都壓在一家,那一陣子就只能放假。可參考 OpenAI 公開狀態頁 的歷史紀錄;Anthropic 的服務狀態則在 status.anthropic.com。
第四是結構化輸出與長文體驗的本質差異。OpenAI 的 Function Calling 與 Structured Outputs 在 schema 強約束下幾乎不會壞,這在串接資料庫、發票、CRM 工具時很關鍵;Claude 在長文連貫性、語氣自然度、繁體中文表達這幾條上有實測優勢。一個工具型、一個生成型,硬塞同一個任務只會兩邊都拉到中間值。

OpenAI 跟 Claude 2026 強項對照
下面這份對照表是我們這幾個月跑 n8n workflow 時抓出來的實戰結論,不是廠商頁面抄的:
| 任務類型 | 推薦模型 | 原因 |
|---|---|---|
| 結構化 JSON 輸出 | OpenAI(GPT-4o, Structured Outputs) | schema 強約束、function call 穩定 |
| 工具呼叫鏈 | OpenAI | tool_choice 與 parallel_tool_calls 成熟 |
| 長文寫作(1000 字以上) | Claude(Sonnet 4 / Opus 4) | 段落連貫、語氣穩定、不太罐頭 |
| 繁體中文敘事 | Claude | 用詞自然,較少中港腔混雜 |
| 程式碼推理與重構 | Claude | 大上下文 + 推理深度 |
| 任務意圖分類 | OpenAI(gpt-4o-mini) | 快、便宜、分類準 |
| 文件比對 / 大檔分析 | Claude(200K context) | 一次塞整份文件不切片 |
| 客服回應第一線 | OpenAI(mini)+ 升級到 Claude | 先快回,難題升級 |
| 即時翻譯 / 短回覆 | OpenAI mini | 延遲低 |
| 安全審核 / 敏感內容 | Claude | 拒絕策略較細緻、誤殺較少 |
要注意:這張表會隨版本變動。OpenAI 推 GPT-5 系列後,function call 跟 structured output 的優勢還會放大;Anthropic 的 Claude 4.6 之後上下文擴到 1M,文件分析的成本會再降。每季度都建議重新跑一次任務基準測試,不要綁死。
新手的決策捷徑可以記成一句:「會被機器繼續吃的東西丟 OpenAI,會被人類讀的東西丟 Claude」。前者要結構正確,後者要讀起來順。
外部基準資料可參考 Artificial Analysis 的模型比較 與 LMSys Chatbot Arena,定期更新各家在分類、推理、長文上的盲測排名。
n8n 雙 LLM 路由的 3 種架構
n8n 把 LLM 抽成 node,這給了路由很大彈性。以下三種架構從簡單到完整,請依團隊規模選。詳細 cluster 拆解可看 n8n 雙 LLM 路由:用 Switch + AI Classifier 做動態派發。
架構 1:靜態 Switch 路由(適合 1~3 種固定任務)
最簡單的版本:用 webhook 拿到任務後,加一個 Switch node 看 body.task_type 欄位,分支到 OpenAI 或 Claude 的 chat node。
Webhook → Switch (task_type)
├─ "summary" → Claude Sonnet
├─ "extract" → OpenAI GPT-4o (Structured Output)
└─ "translation"→ OpenAI gpt-4o-mini
→ Merge → Respond to Webhook優點:邏輯清楚、好 debug、零路由成本。缺點:呼叫端要先知道 task_type,前端或上游系統不一定有這欄位。
實作小技巧:把 system prompt 集中在 n8n 的 Set node 統一管理,不要散落在每個 chat node 裡。日後改 prompt 只改一處,避免「Claude 那邊改了,OpenAI 這邊忘了」。
架構 2:AI Classifier 動態路由(適合不確定任務型態的場景)
呼叫端只丟一段自然語言(例如客服訊息、員工提問),先過一個便宜的分類器決定走哪條路:
Webhook → OpenAI Chat (gpt-4o-mini, 分類)
→ Switch (intent)
├─ "factual_lookup" → RAG → Claude Sonnet 整理答案
├─ "creative_writing" → Claude Opus
├─ "structured_form" → OpenAI GPT-4o (Schema 約束)
└─ "small_talk" → OpenAI mini
→ Respond to Webhook關鍵設計:分類器一定要用便宜快速的模型(GPT-4o-mini、Claude Haiku),不要用 GPT-4o 做意圖分類,那是把 5 倍成本浪費在不需要的環節。分類 prompt 寫成嚴格列舉式,搭配 OpenAI 的 Structured Outputs 強制只回 enum 之一:
{
"name": "intent_classification",
"strict": true,
"schema": {
"type": "object",
"properties": {
"intent": {
"type": "string",
"enum": ["factual_lookup", "creative_writing", "structured_form", "small_talk"]
},
"confidence": { "type": "number" }
},
"required": ["intent", "confidence"]
}
}confidence < 0.7 時走預設分支或退回給人類,避免低信心結果污染後續節點。
架構 3:Primary + Fallback 雙保險(適合 production critical path)
正式上線後最重要的不是省錢,而是 SLA。任何一家 API 掛掉都要能切換:
Webhook → OpenAI Chat (主)
→ IF (success?)
├─ true → Format → Respond
└─ false → Claude Chat (備) → Format → Respondn8n 的 IF node 可以判斷上游 node 的 success 屬性,OpenAI 失敗(429、5xx、timeout)時自動切到 Claude。這個架構可以再疊加:兩家都失敗時降級到模板式回覆並把 case 推到人工處理佇列。
進階版:用 n8n 的 Error Trigger 接全工作流的錯誤,集中送到 Slack 或 LINE 告警,這樣你不用每條 workflow 都自己寫一套錯誤通知。錯誤模式可以參考 N8N 工作流錯誤處理 6 種模式。
路由架構選擇表
| 團隊狀況 | 推薦架構 |
|---|---|
| MVP 階段、任務 ≤ 3 種、不需 SLA | 架構 1:靜態 Switch |
| 客服或 SaaS、任務多元、需要動態 | 架構 2:AI Classifier |
| 正式 production、有付費客戶 | 架構 1 或 2 + 架構 3 fallback |
實戰案例:3 條真實 workflow
案例 1:客服自動化(架構 2 + 3)
某 SaaS 公司每天客服訊息 3000 則。原本全用 GPT-4o,月帳單約 USD 1800。改成雙 LLM 後:
- gpt-4o-mini 做意圖分類(每訊息 ~200 tokens)
- 70% factual 走 RAG → Claude Sonnet 整理(長文體驗更好)
- 20% structured 走 GPT-4o(CRM 表單填寫)
- 10% small talk 走 mini 直接回
月帳單降到 USD 760,且回覆滿意度(手動抽樣評分)反而上升。重點:每段任務都用「夠用且擅長」的模型,不要全部用最貴的。
案例 2:行銷內容生產(架構 1)
每週要產 5 篇 SEO 長文 + 12 則社群貼文 + 3 支短影片腳本。任務型態固定,用架構 1 直接路由:
- SEO 長文 → Claude Opus(連貫性、長文體驗)
- 社群貼文 → Claude Sonnet(語氣自然、繁體中文穩)
- YouTube 描述 → GPT-4o(要符合特定 schema:title、tags、chapters)
- 標題 hook 生成 → 兩家都跑,再讓 Claude 評分選最好的
效果:每週省下 6 小時人工 fine-tune,內容稿手改幅度 < 15%。
案例 3:內部資料分析(純 Claude)
這個案例反而提醒「雙 LLM 不一定是兩家都用」。某物流公司每天要分析一份 80 頁 PDF 報表,用 Claude 200K context 直接整份塞進去做摘要 + 異常偵測,準確度比切片再餵 GPT-4o 高很多。這時候單一 LLM 反而是對的選擇。
雙 LLM 的本質是「按任務選工具」,不是「強迫使用兩家」。
成本與延遲實算:雙 LLM 真的省錢嗎?
我們用一個常見場景算:每月 10 萬次客服請求,平均每次 800 tokens 輸入、400 tokens 輸出。
全 GPT-4o 方案
- 輸入:100,000 × 800 × USD 2.50 / 1M = USD 200
- 輸出:100,000 × 400 × USD 10 / 1M = USD 400
- 月成本:USD 600
雙 LLM 方案(架構 2)
- 分類:100,000 × 200 × USD 0.15 / 1M(gpt-4o-mini 輸入)= USD 3
- 70% Claude Sonnet(factual):70,000 × 800 × USD 3 / 1M + 70,000 × 400 × USD 15 / 1M = USD 168 + 420 = USD 588
- 20% GPT-4o(structured):20,000 × 800 × USD 2.50 / 1M + 20,000 × 400 × USD 10 / 1M = USD 40 + 80 = USD 120
- 10% mini(small talk):10,000 × 800 × USD 0.15 / 1M + 10,000 × 400 × USD 0.6 / 1M = USD 1.2 + 2.4 = USD 3.6
- 月成本:USD 715
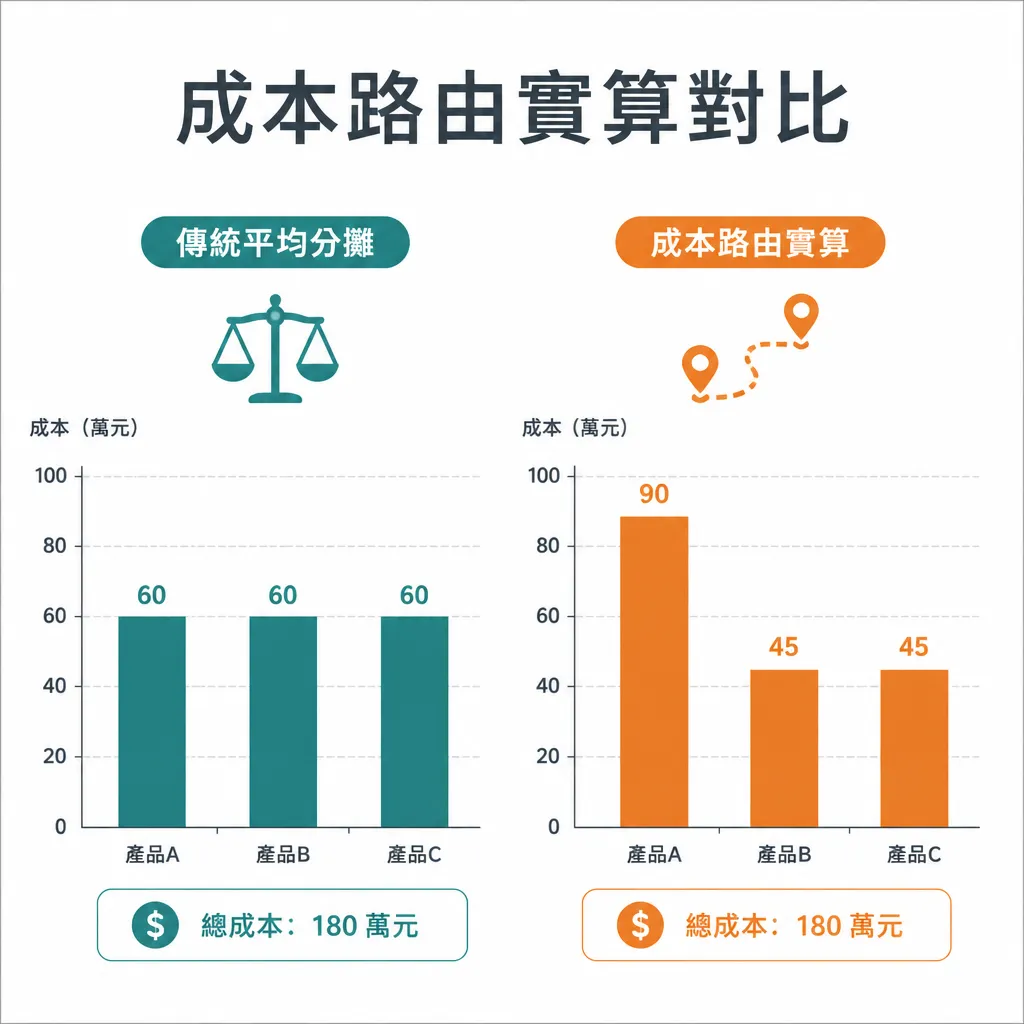
咦,怎麼變貴了?因為 70% 走 Claude Sonnet,Sonnet 輸出單價較 GPT-4o 高。雙 LLM 不一定省錢,要看你的任務分布。
換個分布:如果 60% 是 small talk、20% structured、20% factual:
- 月成本變 USD ≈ 220,省了 60%。
結論:雙 LLM 是「品質 / 成本最佳化」,不是「無腦省錢」。 想真正省,要先做使用量分析,把短任務、分類任務、模板任務先打到便宜模型,再讓貴模型做需要的事。實際定價以 OpenAI Pricing 與 Anthropic Pricing 公布為準,本文數字僅供結構推估。
延遲方面,AI Classifier 路由會多 200~600ms(多一次 API 往返)。要避開這個成本,可以用 n8n 的 Cache node 對重複問題做快取(key = hash(prompt)),命中時零延遲零 token。
雙 LLM 工作流上線前檢查表
正式接到 production 前,請逐條走過:
- API key 雙家準備好:OpenAI、Anthropic 兩組,分別存到 n8n 的 Credentials,不要寫死在 prompt 或 code 裡
- 錯誤處理已加:每個 LLM 節點接 Error Trigger 或 IF 判斷 success
- 延遲預算定義清楚:客服場景建議 < 3 秒總延遲,分類器選 mini / haiku
- 成本上限有 alert:用 OpenAI 的 usage limit 與 Anthropic 的 spend cap 各設一個,避免 prompt injection 把帳單炸開
- Prompt 集中管理:用 n8n Set node 或外部 config 管 system prompt,不要分散
- 任務日誌打點:每次 LLM 呼叫記下 model、tokens、latency、cost,事後才能 tune 路由比例
- fallback 規則寫清楚:兩家都掛時要有降級方案(樣板回覆 / 排隊處理)
- 隱私與合規:客戶資料丟雲端 LLM 前,PII 是否需要脫敏;歐盟客戶資料是否有 EU region 要求
- 版本鎖定:別用
gpt-4o、claude-sonnet-4這種 latest alias,鎖定到具體 snapshot(如gpt-4o-2024-08-06)才不會某天行為突變 - 成本對照表每月更新:兩家都常調價或推新模型,路由比例要跟著重算
常見問題
雙 LLM 工作流會不會比較難維護?
短期會多花 1~2 天熟悉路由邏輯與 IF 判斷,但長期相反——把每個任務的 prompt 跟 model 對齊後,反而更容易 debug,因為「什麼任務出問題就回頭看哪個分支」。比起單一 LLM 一個 prompt 包山包海,分支版本問題範圍更小。
我可以只用 Claude,跳過 OpenAI 嗎?
可以,但會在三件事上吃虧:function call schema 約束、ecosystem 工具(DALL-E、Whisper、TTS)、以及 cost-effective 的 mini 系列分類器。如果你完全不需要這些,純 Claude workflow 也是合理選擇。
兩家都掛掉怎麼辦?
這就是為什麼架構 3 的 fallback 不夠,正式上線還要再多一層:模板式回覆 + 人工排程。例如「目前系統繁忙,已將您的訊息轉給專員,預計 30 分鐘內回覆」這種降級訊息要事先準備。重大客戶建議再準備本地小模型(Llama / Qwen 自架)做最後保底。
延遲多 600ms 對使用者體驗有影響嗎?
對話型客服感受不到,因為人讀字也要時間。但對話 IVR、即時 voice agent、遊戲內 NPC 對話這類場景影響大,建議用架構 1(靜態路由)跳過分類器。
n8n MCP 出來後,雙 LLM 路由還有意義嗎?
更有意義。MCP 讓 Claude Skills 可以變 n8n node,但沒解決「該不該用 Claude」的問題。雙 LLM 路由是「決策層」,MCP 是「執行層」。詳見 n8n MCP integration:把 Claude Skills 變 workflow node。
接下來怎麼做
- 翻一次手上既有 n8n workflow,標記每個 LLM 節點的「任務類型」
- 從那張選型表挑一條最貴的 workflow,先換到雙 LLM 跑一週看結果
- 蒐集一週的 cost / latency / 滿意度數據,再決定是否擴大
- 想要拿可用模板直接改?逛逛我們的 n8n 雙 LLM 模板分類
雙 LLM 不是炫技,是把錢花在對的地方。把這篇收進團隊的 SOP,下次任何人要新做 AI workflow,先問一句:「這一步會被機器吃,還是會被人類讀?」答案就是路由方向。